Двоичное кодирование текстовой информации
Слайды и текст этой презентации
| Слайд №1 | |
 |
Двоичное кодирование текстовой информации Презентацию подготовила Машкина Татьяна Анатольевна, учитель информатики МБОУ «СОШ №92» |
| Слайд №2 | |
 |
Вопросы для повторения Какие виды информации по способу представления вы знаете? Кодирование каких видов информации вы изучили на прошлых уроках? Что принято за единицу количества информации? Назовите производные единицы измерения количества информации. |
| Слайд №3 | |
 |
Двоичное кодирование текстовой информации В 40-е годы прошлого столетия было положено начало созданию вычислительной машины. Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации. |
| Слайд №4 | |
 |
Таинственные знаки
+|| ++|||| +++||| |
| Слайд №5 | |
 |
Двоичное кодирование текстовой информации В памяти компьютера любой текст представляется последовательностью кодов символов, т. е. вместо самой буквы хранится ее номер в кодовой таблице. Изображение же букв и символов сформируется только в момент их вывода на экран или бумагу. |
| Слайд №6 | |
 |
Двоичное кодирование текстовой информации Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255). |
| Слайд №7 | |
 |
Кодовые таблицы Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей. Для разных типов ЭВМ используются различные кодировки |
| Слайд №8 | |
 |
Кодовые таблицы По началу применялось 7-битная кодировка, которая могла представить 128 символов. С распространением IBM PC международным стандартом стала таблица кодировки ASCII (American Standart Code for Information Interchange) – Американский стандартный код для информационного обмена. |
| Слайд №9 | |
 |
Таблица кодировки ASCII Позже она была расширена до 8 бит (256 символов) и дошла в таком виде практически до сегодняшнего дня. При этом первая половина (символы 0-127) были всегда одни и те же, соответствующие стандарту ASCII, а вторая половина таблицы (символы 128-255) менялась в зависимости от страны, где она использовалась. |
| Слайд №10 | |
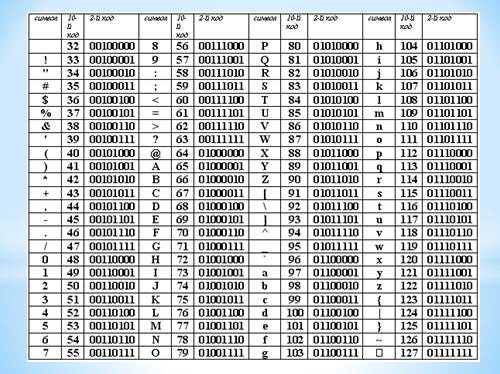 |
Стандартная часть таблицы |
| Слайд №11 | |
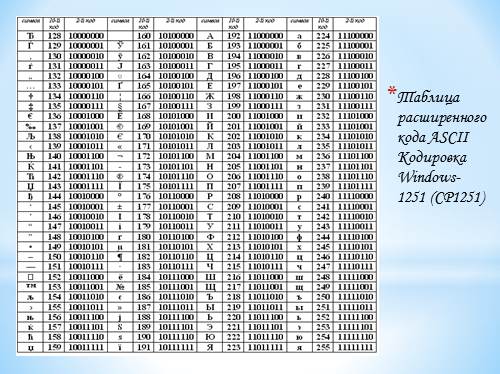 |
Таблица расширенного кода ASCIIКодировка Windows-1251 (CP1251) |
| Слайд №12 | |
 |
Двоичное кодирование текстовой информации в компьютере Для представления текстовой информации достаточно 256 различных символов. N = 2I, 256 = 2I , 28 = 2I ,I = 8 битов Для кодирования каждого знака требуется количество информации, равное 8 битам. Для представления текста в памяти компьютера необходимо представить его в двоичной знаковой системе. Каждому знаку необходимо поставить в соответствие уникальный двоичный код в интервале от 00000000 до 11111111 (в десятичном коде от 0 до 255) |
| Слайд №13 | |
 |
Кодовая таблица Для представления символов и соответствующих им кодов используется кодовая таблица. В качестве стандарта во всем мире принята таблица ASCII (American Standard Code for Information Interchange – Американский стандартный код для обмена информацией). Условно таблица разделена на части: от 0 до 32 коды соответствуют операциям; с 33 по 127 соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания; со 128 по 255 являются национальными. |
| Слайд №14 | |
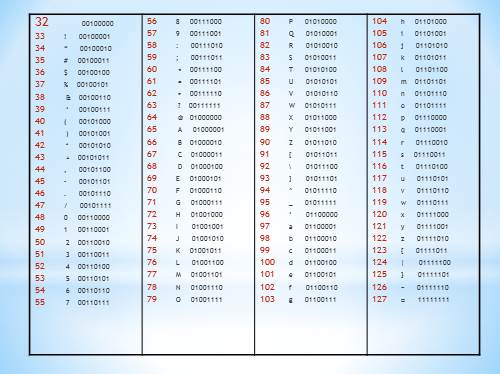 |
00100000 ! 00100001 “ 00100010 # 00100011 $ 00100100 % 00100101 & 00100110 ‘ 00100111 ( 00101000 ) 00101001 * 00101010 + 00101011 , 00101100 — 00101101 . 00101110 / 00101111 0 00110000 1 00110001 2 00110010 3 00110011 4 00110100 5 00110101 6 00110110 7 00110111 8 00111000 9 00111001 : 00111010 ; 00111011 00111110 ? 00111111 @ 01000000 A 01000001 B 01000010 C 01000011 D 01000100 E 01000101 F 01000110 G 01000111 H 01001000 I 01001001 J 01001010 K 01001011 L 01001100 M 01001101 N 01001110 O 01001111 P 01010000 Q 01010001 R 01010010 S 01010011 T 01010100 U 01010101 V 01010110 W 01010111 X 01011000 Y 01011001 Z 01011010 [ 01011011 01011100 ] 01011101 ^ 01011110 _ 01011111 ‘ 01100000 a 01100001 b 01100010 c 01100011 d 01100100 e 01100101 f 01100110 g 01100111 h 01101000 i 01101001 j 01101010 k 01101011 l 01101100 m 01101101 n 01101110 o 01101111 p 01110000 q 01110001 r 01110010 s 01110011 t 01110100 u 01110101 v 01110110 w 01110111 x 01111000 y 01111001 z 01111010 { 01111011 | 01111100 } 01111101 ~ 01111110 ? 11111111 |
| Слайд №15 | |
 |
Принцип последовательного кодирования алфавита: В кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Данное правило соблюдается и в других таблицах кодировки. Благодаря этому и в машинном представлении для символьной информации сохраняется понятие «алфавитный порядок». |
| Слайд №16 | |
 |
Различные кодировки знаков В настоящее время существуют пять различных кодировок для русских букв (Windows, MS-DOS, КОИ-8, Mac, ISO), поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой. В последние годы широкое распространение получил новый международный стандарт кодирования текстовых символов Unicode, который отводит на каждый символ 2 байта (16 битов), что позволило закодировать многие алфавиты в одной таблице. N = 2I, N = 216 , N = 65536 |
| Слайд №17 | |
 |
Пример 1 Буква «i» в таблице кодировки символов имеет десятичный код 105. Что зашифровано последовательностью десятичных кодов: 108 105 110 107? При расшифровке данной последовательности кодов не нужно обращаться к таблице кодировки символов. Необходимо учесть принцип последовательного кодирования алфавитов и вспомнить порядок букв в латинском алфавите (…i, j, k, l, m, n, o, …) Закодировано: «link» |
| Слайд №18 | |
 |
Пример 2 С помощью последовательности десятичных кодов: 99 111 109 112 117 116 101 114 закодировано слово «computer». Какая последовательность десятичных кодов будет соответствовать этому же слову, записанному заглавными буквами? При шифровке слова не пользоваться таблицей кодировки символов. Необходимо учесть, что разница между десятичным кодом строчной буквы латинского алфавита и десятичным кодом соответствующей заглавной буквы равна 32. Если «с» имеет код 99, то «С» имеет код 99-32=67. COMPUTER – 67 79 77 80 85 84 69 82 |
| Слайд №19 | |
 |
Пример 3 Какое количество информации необходимо для кодирования одного символа компьютерного алфавита? Слова «компьютер»? Слова «алфавит»? |
| Слайд №20 | |
 |
Тестовая проверочная работа Вариант 1 1. Полный набор символов, используемый для кодирования, называют: 1) шифром 2) алфавитом 3) синтаксисом 4) семантикой 2. Минимальным объектом, используемым для кодирования текста, является: 1)бит 2) пиксель 3) символ 4) растр 3. Количество битов, необходимое для кодирования одного символа алфавита в коде Unicode, равно: 1) 8 2) 16 3) 32 4) 256 4. Сообщение «урок» содержит следующее количество информации: 1) 4 бита 2) 32 бита 3) 8 байт 4) 32 байта 5. Какие символы могут быть зашифрованы кодами таблицы ASCII 119 и 251? 1) «д» и «ш» 2) «j» и «s» 3) «d» и «D» 4) «w» и «ы» Вариант 2 |
| Слайд №21 | |
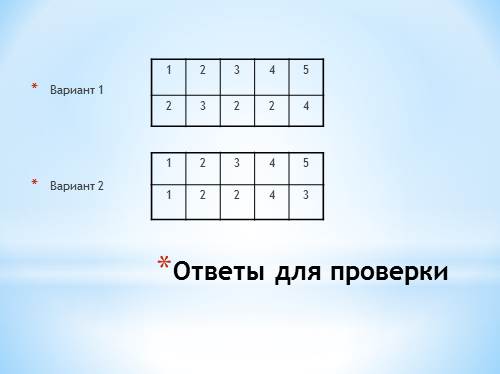 |
Ответы для проверки 1 2 3 4 5 2 3 2 2 4 Вариант 1 Вариант 2 |
| Слайд №22 | |
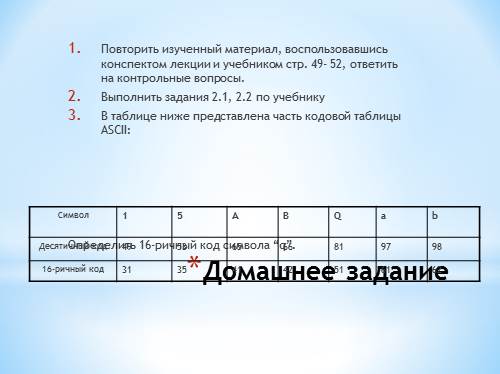 |
Домашнее задание Повторить изученный материал, воспользовавшись конспектом лекции и учебником стр. 49- 52, ответить на контрольные вопросы. Выполнить задания 2.1, 2.2 по учебнику В таблице ниже представлена часть кодовой таблицы ASCII: Определить 16-ричный код символа “q”. Символ 1 5 А В Q a b |
| Слайд №23 | |
 |
Кодовые таблицы В Советском Союзе различные организации и сети, имевшие большое влияние на компьютерный и программный рынок тех времен, создавали свои кодировки (т.е. вторые половины таблицы), содержащие русские символы. |
| Слайд №24 | |
 |
Кодовые таблицы для русских букв В настоящее время существует 5 разных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO). Широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ два байта. С его помощью можно закодировать 65536 (216= 65536 ) различных символов. |
| Слайд №25 | |
 |
Проблемы с кодировками Проблемы с кодировками делятся на несколько типов. Первый тип — это отсутствие информации о кодировке. |
| Слайд №26 | |
 |
Проблемы с кодировками Проблемы второго типа — это когда кодировка в файле указана, но конечная программа такой кодировки не знает. |
| Слайд №27 | |
 |
Проблемы с кодировками Третий тип проблем, наоборот, связан с избытком информации о кодировках. Это актуальная в настоящее время проблема (например, для веб-страниц). |
| Слайд №28 | |
 |
Обратите внимание! Цифры кодируются по стандарту ASCII в двух случаях – при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в другой двоичных код. |
| Слайд №29 | |
 |
Обратите внимание! Возьмем число 57. При использовании в тексте каждая цифра будет представлена своим кодом в соответствии с таблицей ASCII. В двоичной системе это – 0011010100110111. При использовании в вычислениях, код этого числа будет получен по правилам перевода в двоичную систему и получим – 00111001. |
| Слайд №30 | |
 |
Информационный объем текста Сегодня очень многие люди для подготовки писем, документов, статей, книг и пр. используют компьютерные текстовые редакторы. Компьютерные редакторы, в основном, работают с алфавитом размером 256 символов. В этом случае легко подсчитать объем информации в тексте. Если 1 символ алфавита несет 1 байт информации, то надо просто сосчитать количество символов; полученное число даст информационный объем текста в байтах. |
| Слайд №31 | |
 |
Формулы для расчета информационного объема текста I=K?i, где I-информационный объем сообщения K- количество символов в тексте i- информационный вес одного символа 2i = N N- мощность алфавита |
| Слайд №32 | |
 |
Задание 1 Мощность алфавита равна 256. Сколько Кбайт памяти потребуется для сохранения 160 страниц текста, содержащего в среднем 192 символа на каждой странице? |
| Слайд №33 | |
 |
Задание 1’ Мощность алфавита равна 64. Сколько Кбайт памяти потребуется, чтобы сохранить 128 страниц текста, содержащего в среднем 256 символов на каждой странице? |
| Слайд №34 | |
 |
Задание 2 Объем сообщения – 7,5 Кбайт. Известно, что данное сообщение содержит 7680 символов. Какова мощность алфавита? |
| Слайд №35 | |
 |
Задание 2’ Объем сообщения равен 11 Кбайт. Сообщение содержит 11264 символа. Какова мощность алфавита? |
| Слайд №36 | |
 |
Задание 3 Племя Мумбу-Юмбу использует алфавит из букв: ? ? ? ? ? ? ? ? ? ? ? ? ? ?, точки и для разделения слов используется пробел. Сколько информации несет свод законов племени, если в нем 12 строк и в каждой строке по 20 символов? |
| Слайд №37 | |
 |
Задание 3’ Для кодирования секретного сообщения используются 12 специальных значков-символов. При этом символы кодируются одним и тем же минимально возможным количеством бит. Чему равен информационный объем сообщения длиной в 256 символов? |
| Слайд №38 | |
 |
Вопросы и задания: В чем заключается кодирование текстовой информации в компьютере? Закодируйте с помощью ASCII-кода свою фамилию, имя, номер класса. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения из пушкинского четверостишия: Певец-Давид был ростом мал, Но повалил же Голиафа! |
| Слайд №39 | |
 |
Используемая литература Учебник Угринович Н.Д. Информатика и ИКТбазовый курс 9 класс; Яндекс-картинка Изображение 2 Изображение 3 Изображение 4 Изображение 5 Изображение 6 http://inn.h1.ru/topic.shtml?h1=16&h2=7 http://www.galaktionoff.ru/unpub/TTF.htm http://www.infospir.ru/articles/chto_takoe_kodirovka_2.php http://gym1.pupils.ru/img_school/gym1/Ekzamen10/variant1.pdf |


